
Query Translation - RAG
References - Overview of latest RAG techniques by Lance Martin (Software Engineer at LangChain)
Initial setup
!pip install langchain_community tiktoken langchain-openai langchainhub chromadb langchain
import os
os.environ['LANGCHAIN_TRACING_V2'] = 'true'
os.environ['LANGCHAIN_ENDPOINT'] = 'https://api.smith.langchain.com'
os.environ['LANGCHAIN_API_KEY'] = 'your_key'
os.environ['OPENAI_API_KEY'] = 'your_key'
Load the documents and setup a retriever
import bs4
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
),
)
blog_docs = loader.load()
# Split
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=300,
chunk_overlap=50)
# Make splits
splits = text_splitter.split_documents(blog_docs)
# Index
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
vectorstore = Chroma.from_documents(documents=splits,
embedding=OpenAIEmbeddings())
retriever = vectorstore.as_retriever()
Multi Query
Retrieval may produce different results with subtle changes in query wording or if the embeddings do not capture the semantics of the data well. To address this problem we can produce multiple queries from a single user question and do potentially multiple retrievals. 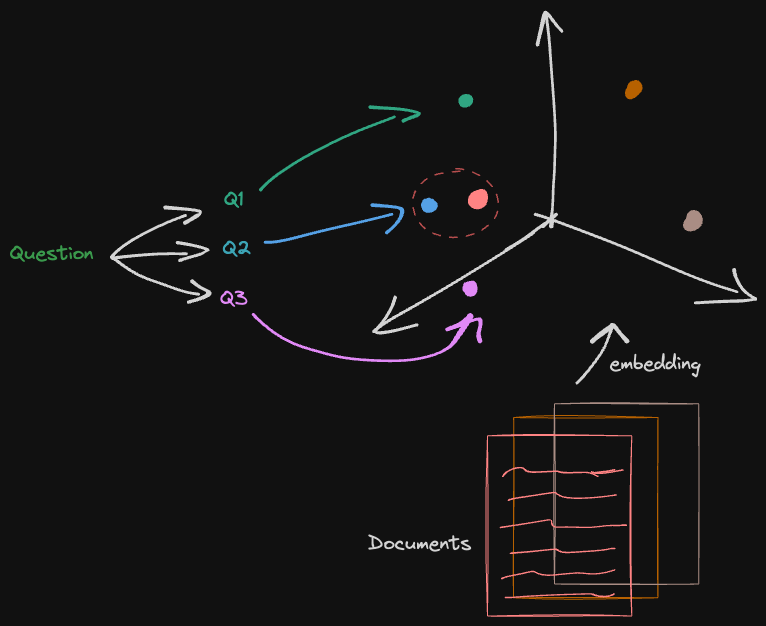
Creating multi-queries from a single question using a prompt and LLM
from langchain.prompts import ChatPromptTemplate
# Multi Query: Different Perspectives
template = """You are an AI language model assistant. Your task is to generate five
different versions of the given user question to retrieve relevant documents from a vector
database. By generating multiple perspectives on the user question, your goal is to help
the user overcome some of the limitations of the distance-based similarity search.
Provide these alternative questions separated by newlines. Original question: {question}"""
prompt_perspectives = ChatPromptTemplate.from_template(template)
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
generate_queries = (
prompt_perspectives
| ChatOpenAI(temperature=0)
| StrOutputParser()
| (lambda x: x.split("\n"))
)
The retriever is receiving a list of queries therefore use .map() to apply multiple retrievals. The result are documents from multiple retrievals using the different queries. The get_unique_union makes sure the result does not have duplicated documents.
from langchain.load import dumps, loads
def get_unique_union(documents: list[list]):
""" Unique union of retrieved docs """
# Flatten list of lists, and convert each Document to string
flattened_docs = [dumps(doc) for sublist in documents for doc in sublist]
# Get unique documents
unique_docs = list(set(flattened_docs))
# Return
return [loads(doc) for doc in unique_docs]
# Retrieve
question = "What is task decomposition for LLM agents?"
retrieval_chain = generate_queries | retriever.map() | get_unique_union
docs = retrieval_chain.invoke({"question":question})
len(docs)
output:
6
Connect the retrieval_chain (which returns the relevant documents) with a new prompt template and pass it to the LLM to generate an answer.
from operator import itemgetter
from langchain_openai import ChatOpenAI
from langchain_core.runnables import RunnablePassthrough
# RAG
template = """Answer the following question based on this context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
llm = ChatOpenAI(temperature=0)
final_rag_chain = (
{"context": retrieval_chain,
"question": itemgetter("question")}
| prompt
| llm
| StrOutputParser()
)
final_rag_chain.invoke({"question":question})
Output:
Task decomposition for LLM agents involves breaking down large tasks into smaller, manageable subgoals. This enables efficient handling of complex tasks by the agent. Task decomposition can be done by LLM with simple prompting, using task-specific instructions, or with human inputs.
RAG Fusion
Again, multi-queries
from langchain.prompts import ChatPromptTemplate
# RAG-Fusion: Related
template = """You are a helpful assistant that generates multiple search queries based on a single input query. \n
Generate multiple search queries related to: {question} \n
Output (4 queries):"""
prompt_rag_fusion = ChatPromptTemplate.from_template(template)
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
generate_queries = (
prompt_rag_fusion
| ChatOpenAI(temperature=0)
| StrOutputParser()
| (lambda x: x.split("\n"))
)
Reciprocal Rank Fusion - set of unique documents from the different retrievals but ranked. If we had a big number of docs we could filter by getting only the top 10 for example.
from langchain.load import dumps, loads
def reciprocal_rank_fusion(results: list[list], k=60):
""" Reciprocal_rank_fusion that takes multiple lists of ranked documents
and an optional parameter k used in the RRF formula """
# Initialize a dictionary to hold fused scores for each unique document
fused_scores = {}
# Iterate through each list of ranked documents
for docs in results:
# Iterate through each document in the list, with its rank (position in the list)
for rank, doc in enumerate(docs):
# Convert the document to a string format to use as a key (assumes documents can be serialized to JSON)
doc_str = dumps(doc)
# If the document is not yet in the fused_scores dictionary, add it with an initial score of 0
if doc_str not in fused_scores:
fused_scores[doc_str] = 0
# Retrieve the current score of the document, if any
previous_score = fused_scores[doc_str]
# Update the score of the document using the RRF formula: 1 / (rank + k)
fused_scores[doc_str] += 1 / (rank + k)
# Sort the documents based on their fused scores in descending order to get the final reranked results
reranked_results = [
(loads(doc), score)
for doc, score in sorted(fused_scores.items(), key=lambda x: x[1], reverse=True)
]
# Return the reranked results as a list of tuples, each containing the document and its fused score
return reranked_results
retrieval_chain_rag_fusion = generate_queries | retriever.map() | reciprocal_rank_fusion
docs = retrieval_chain_rag_fusion.invoke({"question": question})
len(docs)
Output:
7
Generation with RAG fusion
from langchain_core.runnables import RunnablePassthrough
# RAG
template = """Answer the following question based on this context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
final_rag_chain = (
{"context": retrieval_chain_rag_fusion,
"question": itemgetter("question")}
| prompt
| llm
| StrOutputParser()
)
final_rag_chain.invoke({"question":question})
Decomposition
Recursively
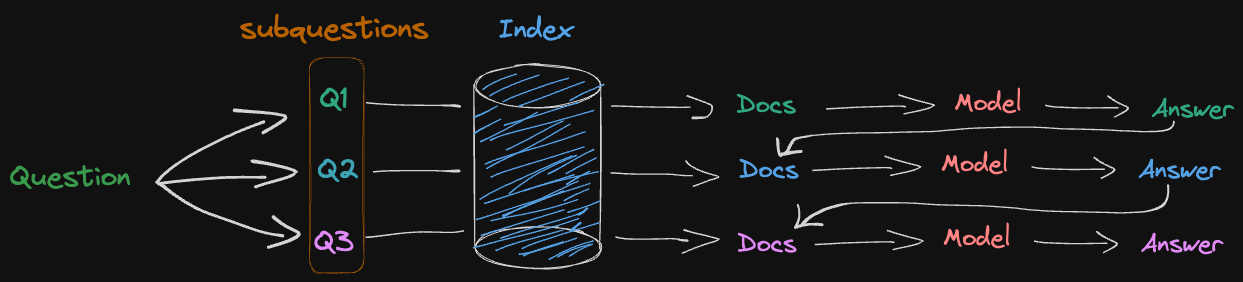 Decomposing the problem into sub-problems and solving them sequentially
Decomposing the problem into sub-problems and solving them sequentially
Prompt to generate subquestions
from langchain.prompts import ChatPromptTemplate
# Decomposition
template = """You are a helpful assistant that generates multiple sub-questions related to an input question. \n
The goal is to break down the input into a set of sub-problems / sub-questions that can be answered in isolation. \n
Generate multiple search queries related to: {question} \n
Output (3 queries):"""
prompt_decomposition = ChatPromptTemplate.from_template(template)
Generate subquestions chain
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
# LLM
llm = ChatOpenAI(temperature=0)
# Chain
generate_queries_decomposition = ( prompt_decomposition | llm | StrOutputParser() | (lambda x: x.split("\n")))
# Run
question = "What are the main components of an LLM-powered autonomous agent system?"
questions = generate_queries_decomposition.invoke({"question":question})
questions
Output:
['1. What is LLM technology and how does it work in autonomous agent systems?',
'2. What are the specific components that make up an LLM-powered autonomous agent system?',
'3. How do the main components of an LLM-powered autonomous agent system interact with each other to enable autonomous behavior?']
Prompt to send to answer generation with previous subquestions and answers plus current relevant document
# Prompt
template = """Here is the question you need to answer:
\n --- \n {question} \n --- \n
Here is any available background question + answer pairs:
\n --- \n {q_a_pairs} \n --- \n
Here is additional context relevant to the question:
\n --- \n {context} \n --- \n
Use the above context and any background question + answer pairs to answer the question: \n {question}
"""
decomposition_prompt = ChatPromptTemplate.from_template(template)
Connecting all together. In the for loop after each answer, the question-pair is saved so it can be used as context for the next question.
from operator import itemgetter
from langchain_core.output_parsers import StrOutputParser
def format_qa_pair(question, answer):
"""Format Q and A pair"""
formatted_string = ""
formatted_string += f"Question: {question}\nAnswer: {answer}\n\n"
return formatted_string.strip()
# llm
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
q_a_pairs = ""
for q in questions:
rag_chain = (
{"context": itemgetter("question") | retriever,
"question": itemgetter("question"),
"q_a_pairs": itemgetter("q_a_pairs")}
| decomposition_prompt
| llm
| StrOutputParser())
answer = rag_chain.invoke({"question":q,"q_a_pairs":q_a_pairs})
q_a_pair = format_qa_pair(q,answer)
q_a_pairs = q_a_pairs + "\n---\n"+ q_a_pair
Individually
 Answer each sub-question individually
Answer each sub-question individually
from langchain import hub
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough, RunnableLambda
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
# RAG prompt
prompt_rag = hub.pull("rlm/rag-prompt")
def retrieve_and_rag(question,prompt_rag,sub_question_generator_chain):
"""RAG on each sub-question"""
# Use our decomposition /
sub_questions = sub_question_generator_chain.invoke({"question":question})
# Initialize a list to hold RAG chain results
rag_results = []
for sub_question in sub_questions:
# Retrieve documents for each sub-question
retrieved_docs = retriever.get_relevant_documents(sub_question)
# Use retrieved documents and sub-question in RAG chain
answer = (prompt_rag | llm | StrOutputParser()).invoke({"context": retrieved_docs, "question": sub_question})
rag_results.append(answer)
return rag_results,sub_questions
# Wrap the retrieval and RAG process in a RunnableLambda for integration into a chain
answers, questions = retrieve_and_rag(question, prompt_rag, generate_queries_decomposition)
Answer the original question using the subquestions-answer pairs
def format_qa_pairs(questions, answers):
"""Format Q and A pairs"""
formatted_string = ""
for i, (question, answer) in enumerate(zip(questions, answers), start=1):
formatted_string += f"Question {i}: {question}\nAnswer {i}: {answer}\n\n"
return formatted_string.strip()
context = format_qa_pairs(questions, answers)
# Prompt
template = """Here is a set of Q+A pairs:
{context}
Use these to synthesize an answer to the question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
final_rag_chain = (
prompt
| llm
| StrOutputParser()
)
final_rag_chain.invoke({"context":context,"question":question})
Step back
A different approach is using a more general retrieval. This might be helpful when reasoning from general to specific is advantageous. More general questions might be easier to answer and establish a good foundation for the model to be able to answer without errors.
With a system instruction and 2 few shot examples ask the LLM to provide a step-back question.
# Few Shot Examples
from langchain_core.prompts import ChatPromptTemplate, FewShotChatMessagePromptTemplate
examples = [
{
"input": "Could the members of The Police perform lawful arrests?",
"output": "what can the members of The Police do?",
},
{
"input": "Jan Sindel’s was born in what country?",
"output": "what is Jan Sindel’s personal history?",
},
]
# We now transform these to example messages
example_prompt = ChatPromptTemplate.from_messages(
[
("human", "{input}"),
("ai", "{output}"),
]
)
few_shot_prompt = FewShotChatMessagePromptTemplate(
example_prompt=example_prompt,
examples=examples,
)
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"""You are an expert at world knowledge. Your task is to step back and paraphrase a question to a more generic step-back question, which is easier to answer. Here are a few examples:""",
),
# Few shot examples
few_shot_prompt,
# New question
("user", "{question}"),
]
)
Generation the step-back question answer.
generate_queries_step_back = prompt | ChatOpenAI(temperature=0) | StrOutputParser()
question = "What is task decomposition for LLM agents?"
generate_queries_step_back.invoke({"question": question})
Output:
What is the process of breaking down tasks for LLM agents?
Use the step-back question retrieved docs plus original question retrieved documents for answering the original question. You should use the same functions from other examples to get a unique set of docs.
response_prompt_template = """You are an expert of world knowledge. I am going to ask you a question. Your response should be comprehensive and not contradicted with the following context if they are relevant. Otherwise, ignore them if they are not relevant.
# {normal_context}
# {step_back_context}
# Original Question: {question}
# Answer:"""
response_prompt = ChatPromptTemplate.from_template(response_prompt_template)
chain = (
{
# Retrieve context using the normal question
"normal_context": RunnableLambda(lambda x: x["question"]) | retriever,
# Retrieve context using the step-back question
"step_back_context": generate_queries_step_back | retriever,
# Pass on the question
"question": lambda x: x["question"],
}
| response_prompt
| ChatOpenAI(temperature=0)
| StrOutputParser()
)
chain.invoke({"question": question})
Output:
Task decomposition for LLM agents refers to the process of breaking down complex tasks into smaller, more manageable subgoals or steps. This approach allows the agent to efficiently handle intricate tasks by dividing them into simpler components. Task decomposition is essential for LLM-powered autonomous agents as it enables them to plan ahead and navigate through various stages of a task systematically.
In the context of LLM agents, task decomposition can be achieved through various techniques such as Chain of Thought (CoT) and Tree of Thoughts. CoT involves prompting the model to "think step by step" and decompose hard tasks into smaller and simpler steps. This technique transforms big tasks into multiple manageable tasks and provides insights into the model's thinking process. On the other hand, Tree of Thoughts extends CoT by exploring multiple reasoning possibilities at each step, creating a tree structure of thought steps and generating multiple thoughts per step.
Task decomposition can be facilitated by providing simple prompts to the LLM, such as "Steps for XYZ" or "What are the subgoals for achieving XYZ?" Alternatively, task-specific instructions can be used, like "Write a story outline" for writing a novel. Human inputs can also be utilized for task decomposition, allowing for a more interactive and collaborative approach to breaking down tasks.
Overall, task decomposition plays a crucial role in enhancing the performance of LLM agents by enabling them to tackle complex tasks effectively through a structured and organized approach. By breaking down tasks into smaller subgoals, LLM agents can navigate through intricate problems with greater ease and efficiency, ultimately leading to improved task completion and problem-solving capabilities.
HyDE (Hypothetical Document Embeddings)
Given the difference between documents, which are large chunks from publications for example, and questions, which are short and can be ill worded, the retrieval process might not be great at retrieving useful documents.
HyDE is a query translation technique used in RAG (Retrieval-Augmented Generation) to improve retrieval by translating input questions into hypothetical documents. The intuition behind HyDE is that a hypothetical document can be closer to a desired document in a high-dimensional embedding space than the original question.
Generate document from a question
from langchain.prompts import ChatPromptTemplate
# HyDE document genration
template = """Please write a scientific paper passage to answer the question
Question: {question}
Passage:"""
prompt_hyde = ChatPromptTemplate.from_template(template)
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
generate_docs_for_retrieval = (
prompt_hyde | ChatOpenAI(temperature=0) | StrOutputParser()
)
# Run
question = "What is task decomposition for LLM agents?"
generate_docs_for_retrieval.invoke({"question":question})
Retrieve using the hypothetical document
# Retrieve
retrieval_chain = generate_docs_for_retrieval | retriever
retireved_docs = retrieval_chain.invoke({"question":question})
retireved_docs
Generate the answer
# RAG
template = """Answer the following question based on this context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
final_rag_chain = (
prompt
| llm
| StrOutputParser()
)
final_rag_chain.invoke({"context":retireved_docs,"question":question})