
RAG
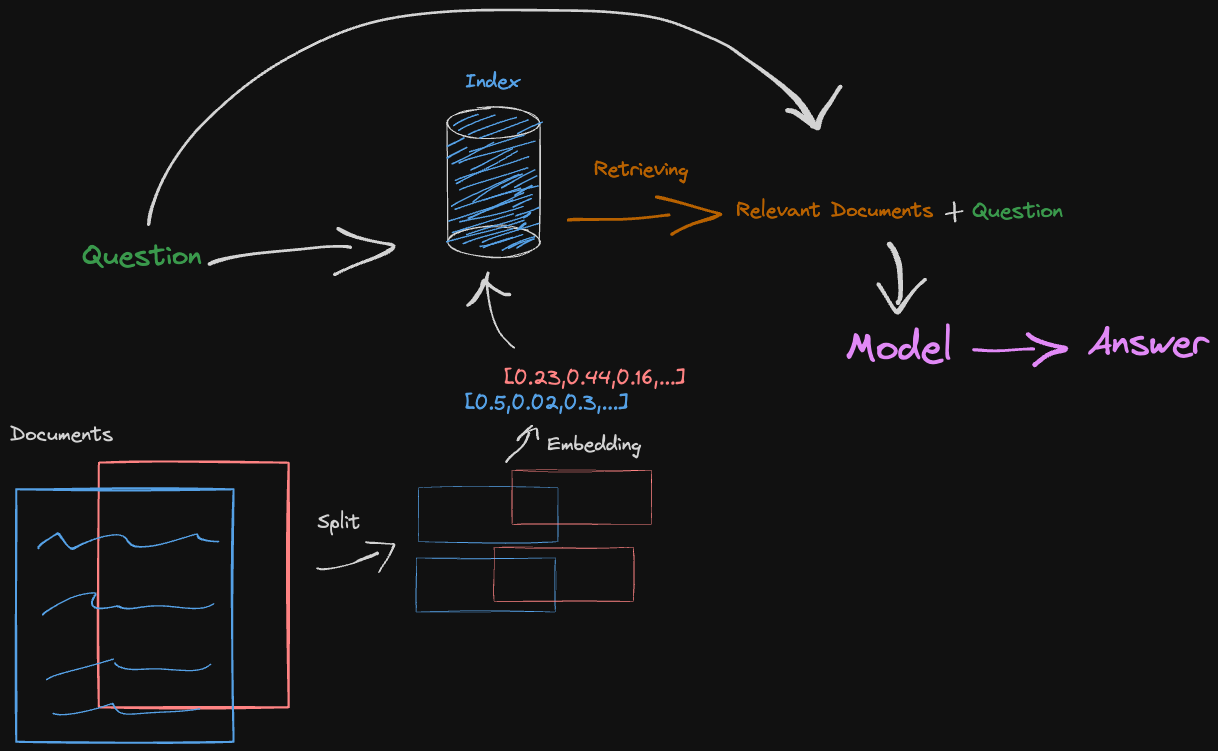
The documents are split to fit into an embedding model. Then retrieved based on similarity score with the question. The model finally gives an answer using both the question and the extra relevant document splits.
Example of basic RAG with LangChain and GPT
! pip install langchain_community tiktoken langchain-openai langchainhub chromadb langchain
import os
os.environ['LANGCHAIN_TRACING_V2'] = 'true'
os.environ['LANGCHAIN_ENDPOINT'] = 'https://api.smith.langchain.com'
os.environ['LANGCHAIN_API_KEY'] = 'yourkey'
os.environ['OPENAI_API_KEY'] = 'yourkey'
import bs4
from langchain import hub
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
The documents text is embedded using machine learned representations. The documents are split into chunks so that the LLM can fit them as input and embed them.
from langchain import PromptTemplate, HuggingFaceHub, LLMChain
#### INDEXING ####
# Load Documents
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
),
)
docs = loader.load()
# Split
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
# Embedding
vectorstore = Chroma.from_documents(documents=splits,
embedding=OpenAIEmbeddings())
retriever = vectorstore.as_retriever()
#### RETRIEVAL and GENERATION ####
# Prompt
prompt = hub.pull("rlm/rag-prompt")
# LLM
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
# Post-processing
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# Chain
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
# Question
rag_chain.invoke("What is Task Decomposition?")
Output:
Task Decomposition is a technique used to break down complex tasks into smaller and simpler steps. This approach helps agents plan ahead and tackle difficult tasks more effectively. Task decomposition can be done through various methods, including using prompting techniques, task-specific instructions, or human inputs.
Step by step
Indexing
# Documents
question = "What kinds of pets do I like?"
document = "My favorite pet is a cat."
import tiktoken
def num_tokens_from_string(string: str, encoding_name: str) -> int:
"""Returns the number of tokens in a text string."""
encoding = tiktoken.get_encoding(encoding_name)
num_tokens = len(encoding.encode(string))
return num_tokens
num_tokens_from_string(question, "cl100k_base")
Output:
8
from langchain_openai import OpenAIEmbeddings
embd = OpenAIEmbeddings()
query_result = embd.embed_query(question)
document_result = embd.embed_query(document)
len(query_result)
Output:
1536
Cosine Similarity
import numpy as np
def cosine_similarity(vec1, vec2):
dot_product = np.dot(vec1, vec2)
norm_vec1 = np.linalg.norm(vec1)
norm_vec2 = np.linalg.norm(vec2)
return dot_product / (norm_vec1 * norm_vec2)
similarity = cosine_similarity(query_result, document_result)
print("Cosine Similarity:", similarity)
Output:
Cosine Similarity: 0.8806521938580575
Document loader
# Load blog
import bs4
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
),
)
blog_docs = loader.load()
Splitter
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=300,
chunk_overlap=50)
# Make splits
splits = text_splitter.split_documents(blog_docs)
Vectorstore
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
vectorstore = Chroma.from_documents(documents=splits,
embedding=OpenAIEmbeddings())
retriever = vectorstore.as_retriever()
Retrieval
Embed the documents using OpenAIEmbeddings and Chroma vectorstore casted as a retriever for the retrieval
# Index
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
vectorstore = Chroma.from_documents(documents=splits,
embedding=OpenAIEmbeddings())
retriever = vectorstore.as_retriever(search_kwargs={"k": 1})
docs = retriever.get_relevant_documents("What is Task Decomposition?")
Generation
Create your template which expects a context and a question. Using LangChain you can pass your retriever as the context to return the relevant documents to the question. The relevant documents and question are used to fill the prompt using the template which is then passed to the LLM to output the answer.
from langchain_openai import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
# Prompt
template = """Answer the question based only on the following context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
prompt
Output:
ChatPromptTemplate(input_variables=['context', 'question'], messages=[HumanMessagePromptTemplate(prompt=PromptTemplate(input_variables=['context', 'question'], template='Answer the question based only on the following context:\n{context}\n\nQuestion: {question}\n'))])
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
rag_chain.invoke("What is Task Decomposition?")
Output:
Task Decomposition is a technique that involves breaking down complex tasks into smaller and simpler steps in order to enhance model performance on complex tasks. It is achieved by instructing the model to "think step by step" and utilize more test-time computation to decompose hard tasks into manageable tasks.